sDiv – das Synthesezentrum am iDiv
sDiv ist das Synthesezentrum für Biodiversitätswissenschaften, eingebettet in das aktive Forschungsumfeld von iDiv. Es ist ein Inkubator für neue Ideen – eine Denkfabrik für die aktuellsten Forschungsfragen im Bereich Biodiversität. Wissenschaftliche Synthese integriert unterschiedliches Wissen, um die Allgemeingültigkeit und Anwendbarkeit von Forschungsergebnissen zu erhöhen und neue Erkenntnisse oder Erklärungen zu generieren. Sie kann vorhandene, aber disparate Daten, Methoden, Theorien und Instrumente auf neue und vielleicht unerwartete Weise zusammenführen. Die Synthese ist ein äußerst vielfältiges Unterfangen, und ihre Definition wird sich je nach Blickwinkel derjenigen, die sie durchführen, unterscheiden. Synthese ist ein Mittel zur Beschleunigung des wissenschaftlichen Verständnisses, das an verschiedenen Orten und auf verschiedenen Ebenen anwendbar ist. In der Biodiversitätsforschung ist es die wissenschaftliche Synthese, die es ermöglicht, Muster, Antworten und Lösungen für einige der wichtigsten Fragen zu finden, mit denen Wissenschaft und Gesellschaft konfrontiert sind.
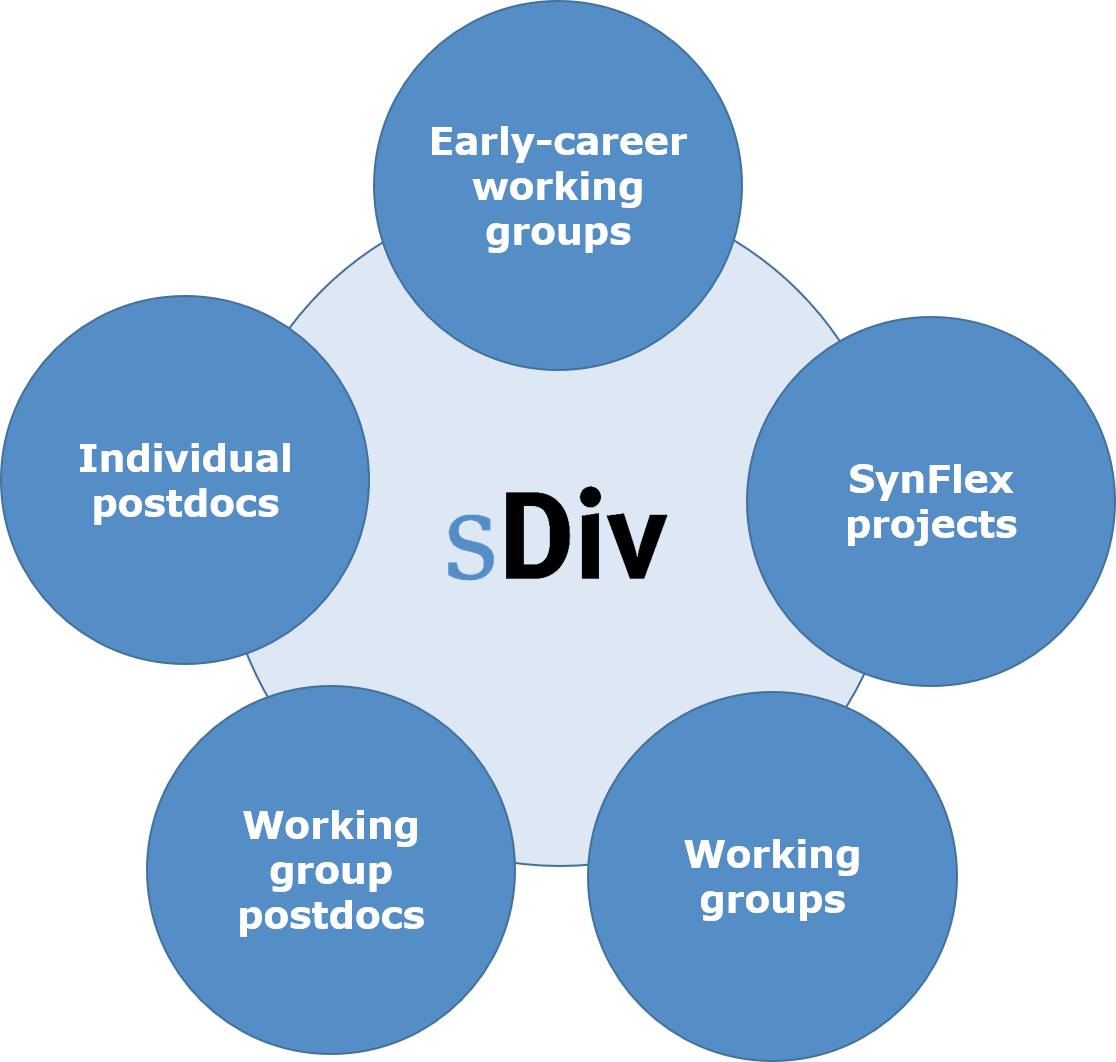
Das sDiv-Synthesezentrum umfasst drei zentrale Instrumente: Treffen internationaler Arbeitsgruppen (Standardformat; Gruppen, die von Nachwuchsforschern geleitet werden), Projekte mit flexiblen Kombinationen von Forschungsansätzen (jenseits von Arbeitsgruppen) und Syntheseprojekte, die von sDiv-Postdocs durchgeführt werden. Es bietet die Möglichkeit, ohne Ablenkung zu arbeiten und sich intensiv mit der Zusammenarbeit und dem Ideenaustausch zu befassen, um über mehrere Jahre Lösungen für die schwierigsten und komplexesten Umweltprobleme der Gesellschaft zu finden.


sDiv Mitarbeiter
Alle sDiv Mitarbeiter
Anschrift
Puschstrasse 4
04103 Leipzig
Germany
Zentrumsleiter
Dr Marten Winter
Phone: +49 341 97 33129
Administrative Assistenz
Carolin Kögler
Phone: +49 341 9733157
Wenn Sie Fragen zu sDiv haben, kontaktieren Sie und gerne!